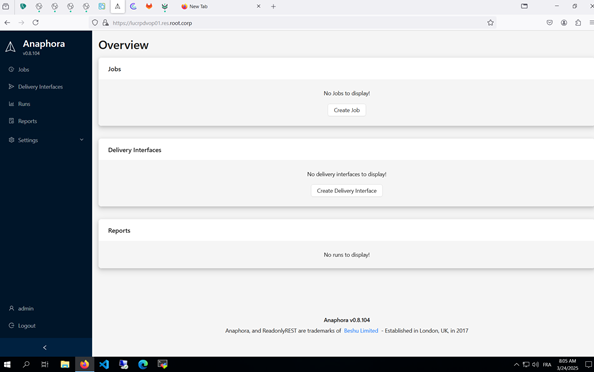
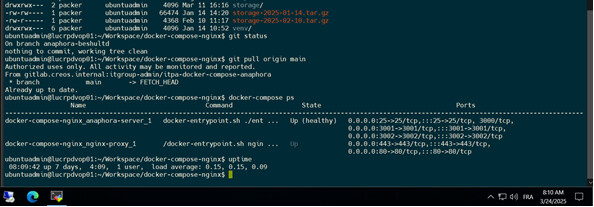
Hello Paul, There is something wrong with our Anaphora instance, I was off for a while and yesterday morning I see there are no more jobs or any configuration present:
I restore a backup from the 14th of March 2025. But I’ve no idea why the configuration was missing
Any idea ?
kr,
Gautier.
nb: I add the idea of creating an API to export configuration; My idea is to schedule a daily export of the configuration to be able to restore everything quickly and it may help us to deploy anaphora on another instance as well etc.
ps: the instance is now running in the latest version available: v0.8.105
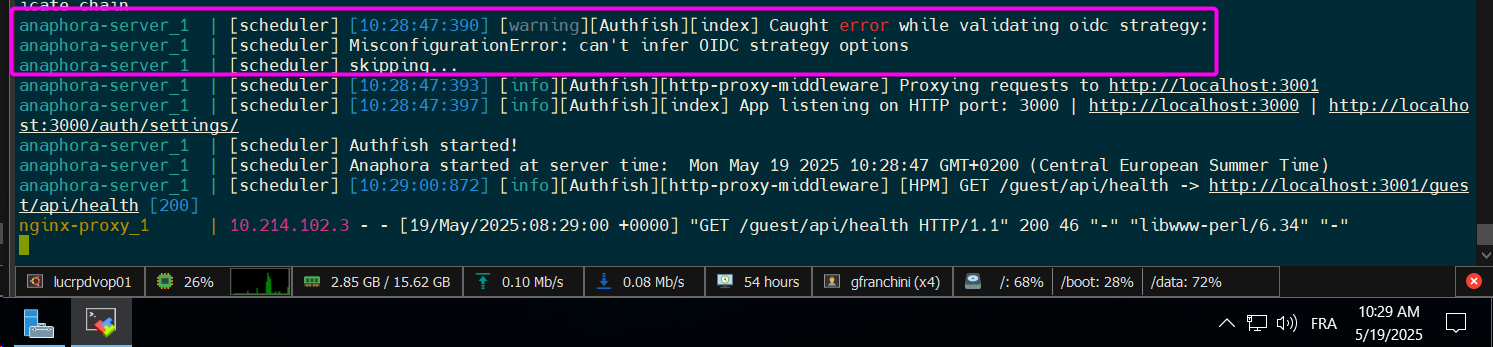
Oh no! Can it be that the container was restarted and the config was stored in a file contained in a directory that was not mounted in the host filesystem?
Anyway +1 for the Backup/Restore API. @gautier.franchini would it be more practical to store that in S3?
Did the system settings also get reset? Like the local users for example.
The system settings are stored in the same folder but in a different file. If they are still the same, this could narrow down the error.
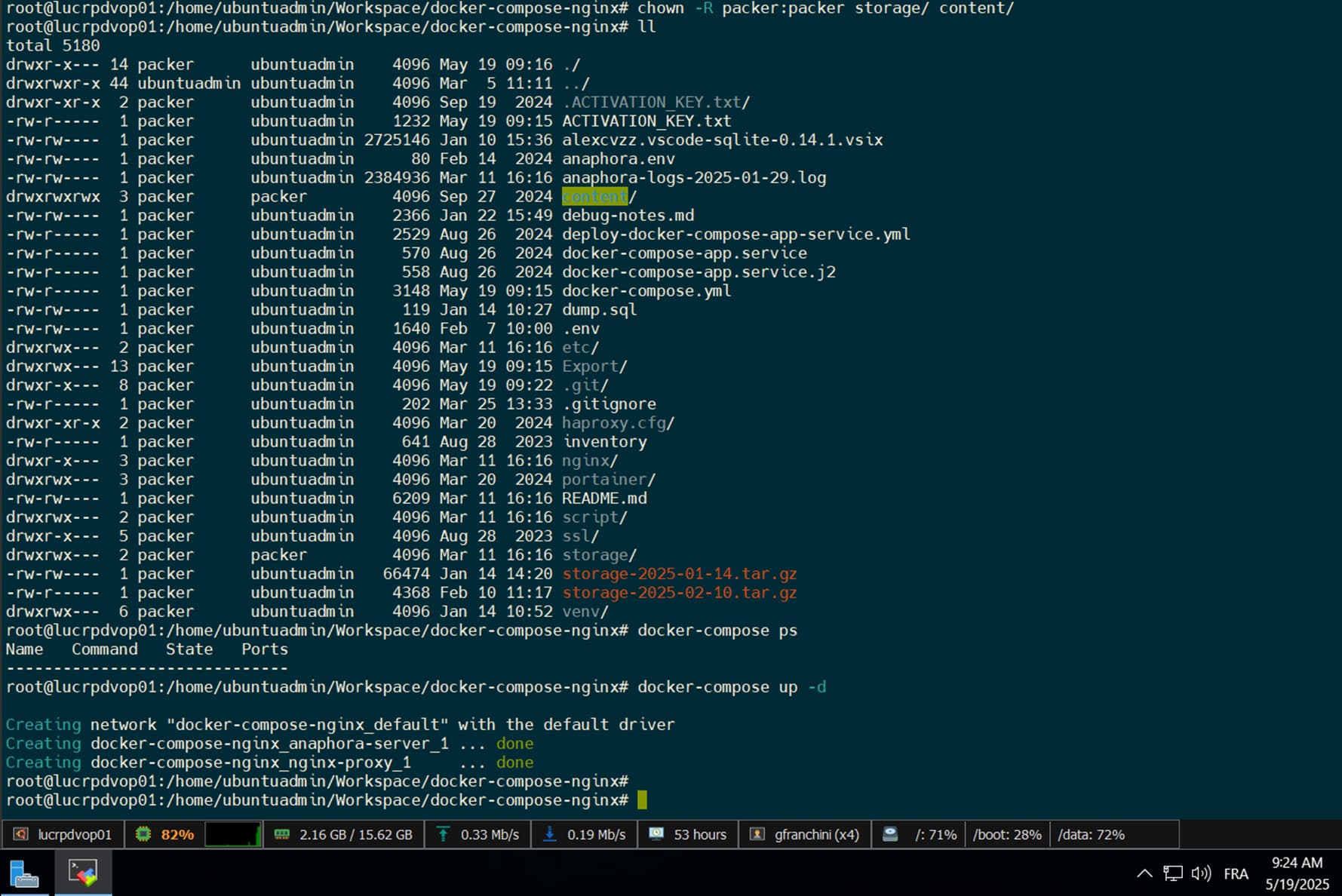
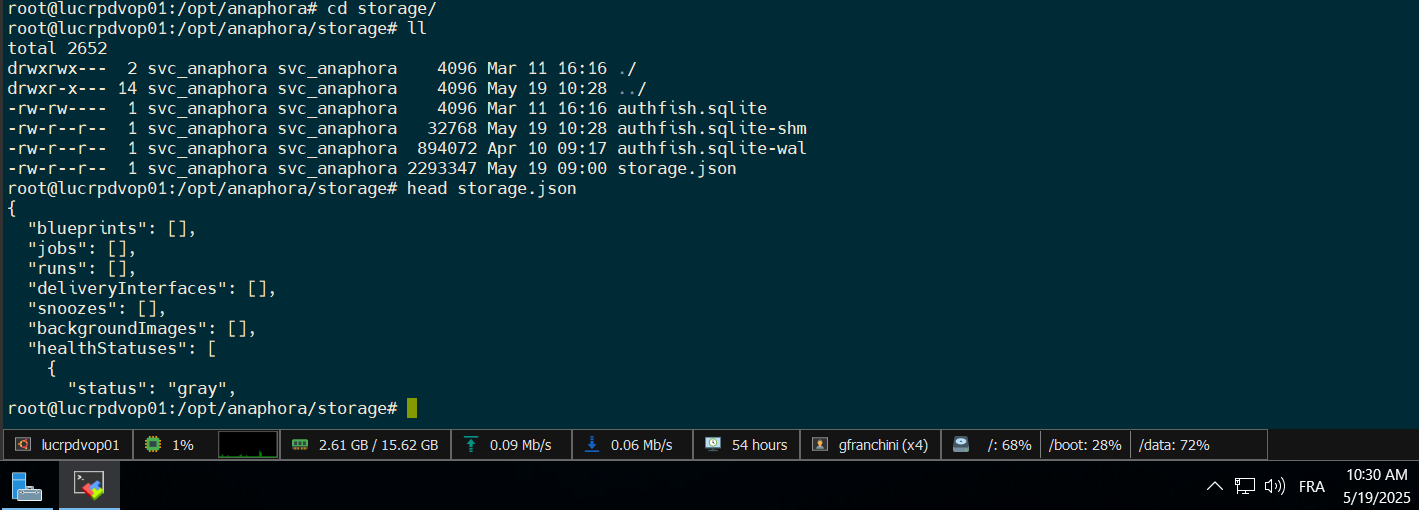
Before you do the import of the backup, can you check the storage folder and see if there is an storage.json file? Does it have any content inside?
This could help identify the issue why the data got lost in the first place.
To avoid any side effects, I now run the anaphora container with a dedicated service accompt; Here are my steps if it can help you update the documentation for future users of anaphora
Create Service Account user (no home dir)
# First, create the group with GID 996
sudo groupadd -g 996 svc_anaphora
# Then, create the user with UID 996, no password, no login shell
sudo useradd -u 996 -g 996 -M -s /bin/false svc_anaphora
# check user
getent passwd svc_anaphora
Explanation:
`-u 996``: sets UID to 996
`-g 996``: sets primary GID to 996
`-M``: do not create a home directory
`-s /bin/false``: no login shell (service account)
As a workaround I restored an export from last week, therefore It could be a nice to have in a future release to be able to:
to possibility to select all jobs we want to re-run and have a button to re-run them all one after the other (not in parallel to avoid any issue if targeting the same kibana/elasticsearch instance for example)
An API to schedule a daily export, a daily backup of the anaphora config to be able to restore the service as quickly as possible
Thank you for the suggestions. I will add them to our board.
I also have an idea of what could have caused the sudden data loss.
I will start working on a patch for that.